Oh, look! It’s Tuesday, and that means another day of ~Spidergram Advent Calendar~ for web analysis nerds.
Yesterday we looked at the basics of setting up a fresh Spidergram project; Today we’ll take a look at the data generated when it crawls a site.
https://github.com/autogram-is/spidergram
First, a bit of background: Spidergram is built on @apify’s excellent Crawlee web-crawling engine and the Playwright browser automation library; it spins up a headless copy of Chrome (or Safari, or Firefox, if that’s how you roll) to render the “real” version of every page.
That’s when Spidergram’s magic kicks in, building not just a record of pages but a map of all the relationships it encounters. They can carry their own information, too — the link between a Resource and a URL it points to can capture where it appeared on a page, for example.
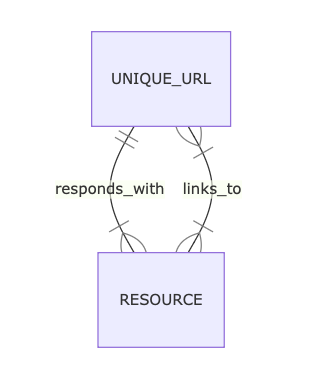
Spidergram can work with other stuff, too — ‘Fragments’ with sub-page content like design components or recurring CMS content; relationships like “Is A Child Of” for hierarchies and “Is A Variation Of” for translation and personalization… But we’ll focus on the basics now.
The URLs, Resources, and relationships Spidergram populates get stored in @arangodb. Rather than flattening everything into rows and columns, it saves each one as a “document” capable of carrying complex data — and when we query the crawl results, we can exploit that.
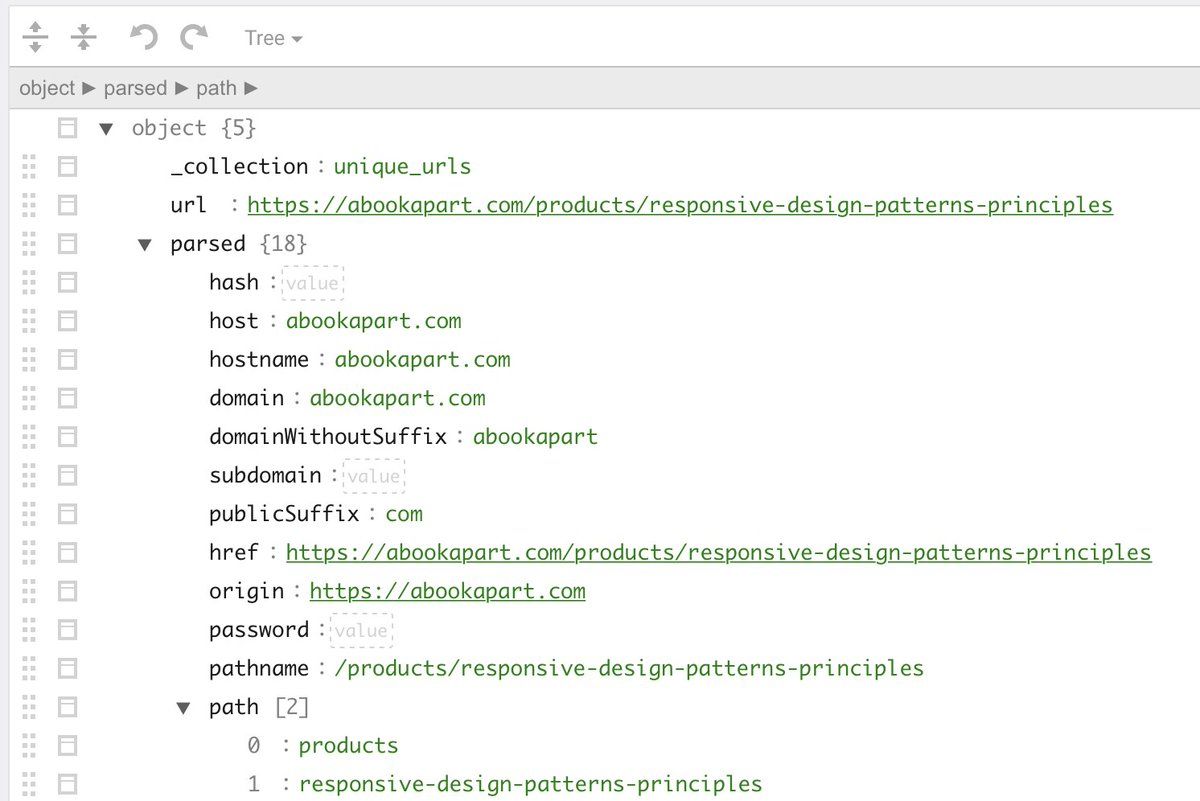 ,
,
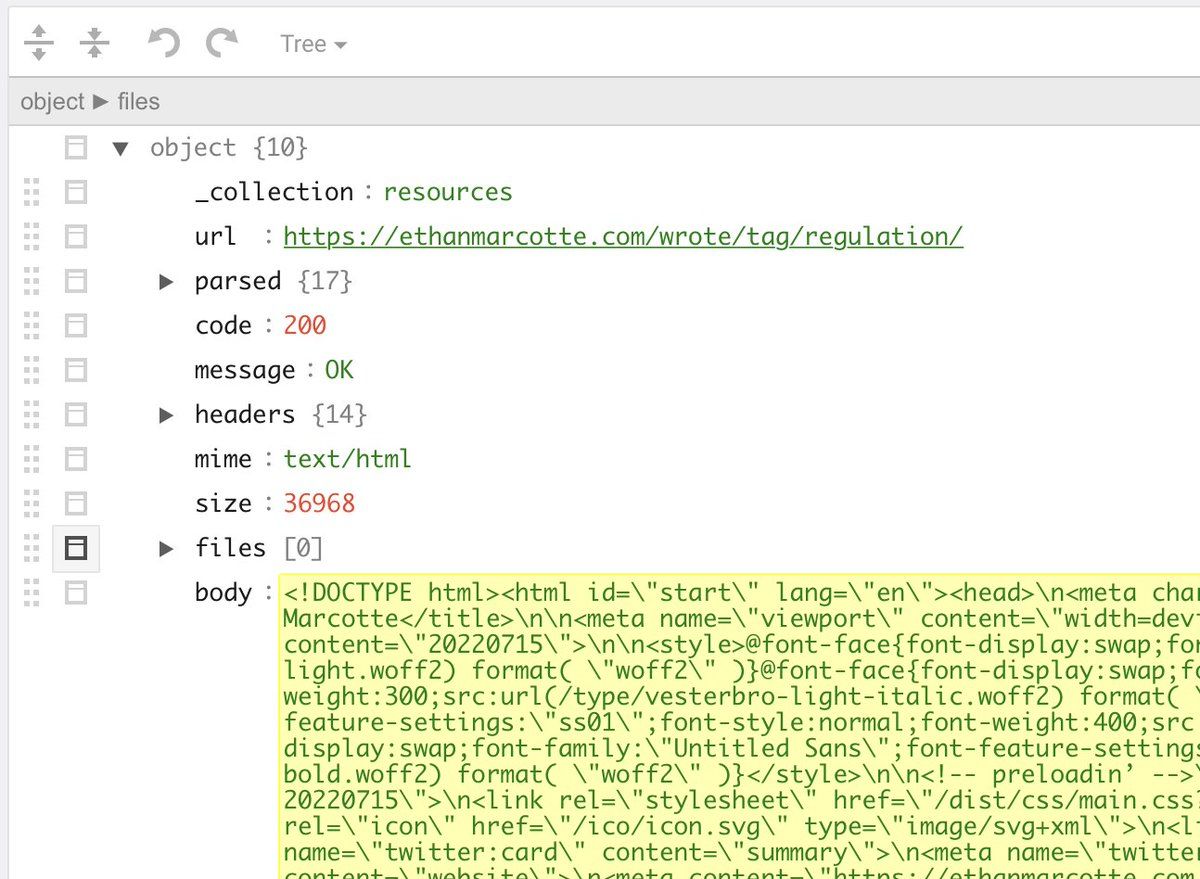
Queries in ArangoDB can dig deep into that structured data for filtering, sorting, and aggregation. A query like:
FOR r IN resources
FILTER r.headers.server LIKE "%Apache%"
RETURN r
…is actually zooming into the structure of the saved HTTP headers, rather than ‘column 12,982’.
ArangoDB’s query language (AQL) has its own pile of rich documentation — and working with Spidergram doesn’t require writing it; there are canned reports and helper functions to cover the basics you’d find in any SEO report. But… when you want to answer complicated questions?
The combination of Arango’s queryable structured documents and Spidergam’s stored web of resources and relationships make it easy to write queries like “Get me a list of outbound links to external sites, grouped by which site and section of OUR properties they live on.”
Today we’ve seen the basic information a crawl generates: URLs, Resources, their relationships…
Tomorrow, we’ll see what Spidergram layers on top of that: stats, http://schema.org structures, analytics data, even CMS-specific metadata you can use to slice and dice a site.
(And soon… very soon! We’ll even see the way the graph structure of the stored information can be used to do wild stuff, like calculate how difficult it is to get from one section of a site to another. Stay tuned…)